如果你最近也在研究 computer use 这一类 Agent,Computer Use for DeepSeek 这个仓库很适合拿来做一遍工程拆解。
它不是一个“把模型接上浏览器就完事”的 demo,而是一套很明确的本地架构:Web UI 负责交互,FastAPI 负责状态和接口,AgentCore 负责模型循环,SafetyPolicy 负责拦截高风险动作,DockerRuntime 负责把操作发到隔离环境里执行,WorkspaceManager 负责把每个 run 的文件关进独立工作区。
我读完这个仓库后的感觉是:它的重点不在“多炫”,而在“怎么把一套 computer use 系统做得可运行、可审查、可控”。这篇文章就按这个思路拆开讲。
先看演示
浏览器任务
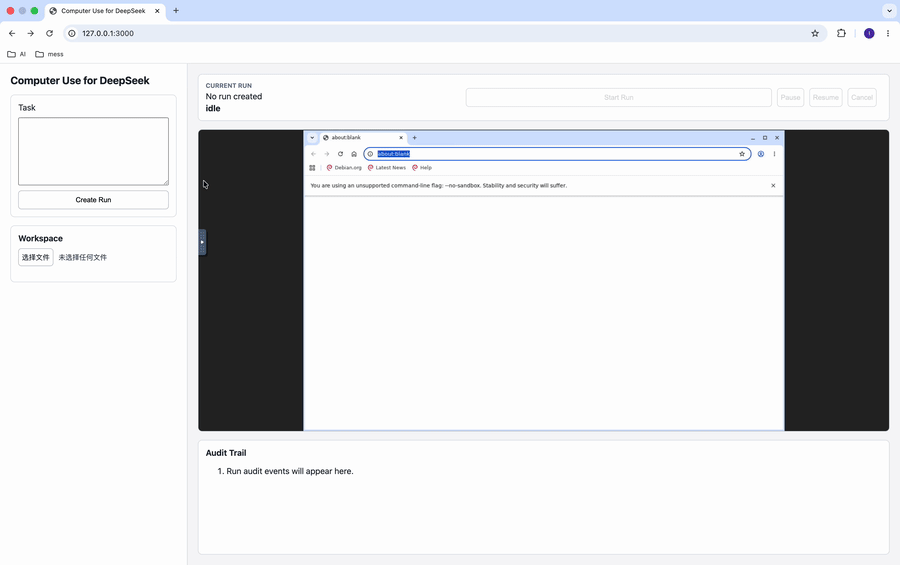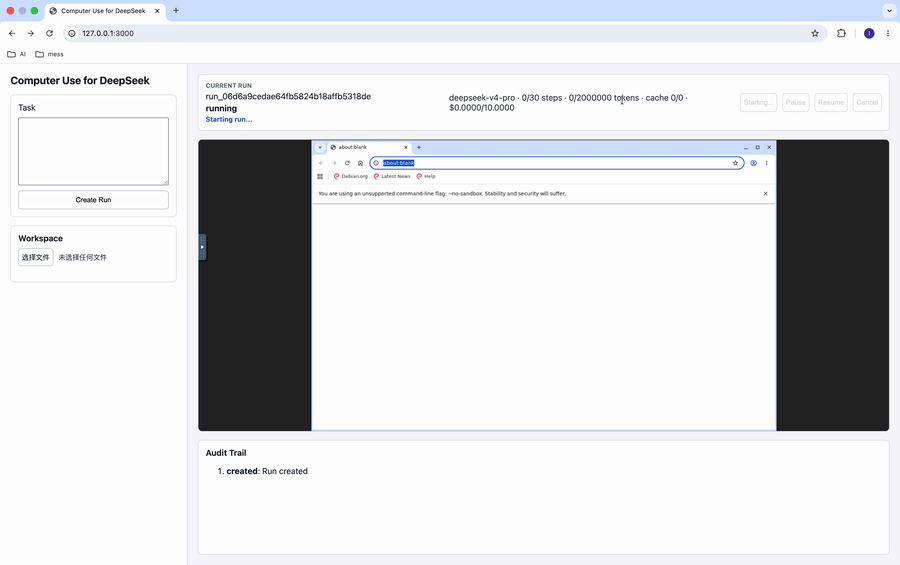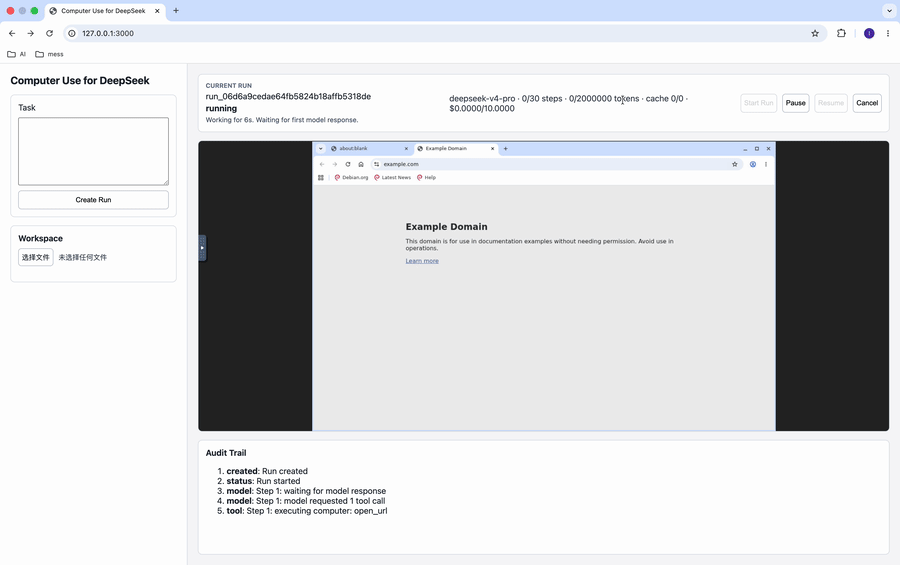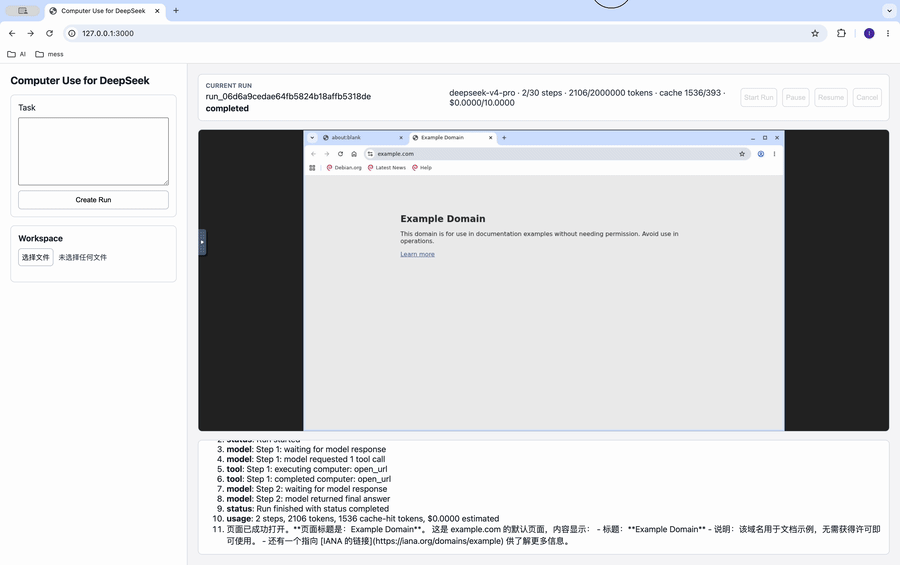
这个 demo 展示的是最典型的 computer use 场景:启动 run、让模型打开网站、观察远程桌面、看事件和状态变化。
文件工作区任务
这个 demo 更能体现工程思路:文件上传、工作区内处理、结果下载,全程不需要把整个用户目录暴露给 AI。
如果你只看一眼体验,这两个 GIF 基本就把项目价值讲完了。
目录
- 一、先看结果:这套东西到底能干什么
- 二、整体架构:UI、API、Agent、Runtime 四层怎么协作
- 三、Agent 循环:每一步都在做什么
- 四、安全层:允许、确认、阻断是怎么分的
- 五、工作区隔离:文件为什么不会乱飞
- 六、这套实现的取舍
- 七、总结
一、先看结果:这套东西到底能干什么
仓库 README 里已经把目标说得很直接:用户在本地打开一个 Web 应用,输入任务,让 DeepSeek 去操作一台隔离电脑,过程中可以看远程桌面、上传文件、下载结果。
这意味着它解决的不是“聊天”,而是“执行”。
你可以把它理解成一个本地版 computer use 运行时:
- 用户在浏览器里下达任务
- 后端把任务交给 DeepSeek
- 模型决定下一步要点哪、敲什么、读什么
- 真正的鼠标键盘动作在沙箱里执行
- 结果再回到模型,继续下一轮
这类系统最难的地方,从来不是“能不能调用 API”,而是:
- 能不能稳定地把模型行为和真实执行环境隔开
- 能不能让用户知道系统现在在做什么
- 能不能把危险动作挡在可控边界内
这个仓库的价值就在这里。
二、整体架构:UI、API、Agent、Runtime 四层怎么协作
整体上可以分成四层:
- UI:给用户看结果和状态
- API:管理 run、文件、事件
- Agent:驱动模型循环
- Runtime:把动作真正落到隔离环境里
2.1 Web UI:只做交互和可观测性
前端负责:
- 创建 run
- 展示任务状态
- 展示事件时间线
- 展示远程桌面
- 上传和下载工作区文件
它不直接碰模型,也不直接碰沙箱。这样做的好处是,前端复杂度被压住了,出问题时也容易定位。
2.2 FastAPI:承接状态和 API
后端入口在 server/src/deepseek_computer_use/main.py,结构很简单:创建 FastAPI 应用、挂载 API 路由、挂载 WebSocket 路由,再暴露一个健康检查接口。
这里最值得注意的不是代码量少,而是职责清楚。路由和启动逻辑被分开后,后续改接口不会把主程序搅成一团。
2.3 AgentCore:真正的决策中枢
AgentCore 是这套系统的心脏。它负责:
- 组装 system prompt 和用户任务
- 调模型
- 解析 tool call
- 执行安全策略
- 调 runtime 真正干活
- 统计 token、成本和步数
这意味着模型不是“单次问答”,而是一个带状态的循环。
2.4 Runtime:把动作落到隔离环境里
DockerRuntime 的职责很清楚:把 tool call 发到运行时容器对应的 action endpoint,让沙箱里的 computer use 服务去实际执行鼠标、键盘、浏览器、文件操作。
核心点在于,它不自己模拟电脑,而是把执行交给独立 runtime。这样主服务和执行环境就分离了,后者崩了也更容易重启。
三、Agent 循环:每一步都在做什么
看 server/src/deepseek_computer_use/agent/core.py,整个流程其实就是一个受控循环。
3.1 起步:system prompt + 用户任务
run() 会先把消息组装成 system message 和 user message,然后进入循环。
这说明它不是“靠前端堆 prompt”,而是把所有控制逻辑收敛在后端 Agent 里。这个设计更稳,也更容易做预算、审计和回放。
3.2 每一步:模型先决定,再执行
每个 step 里,AgentCore 会:
- 调用模型
- 累加 token 与成本
- 判断是否已经输出 final answer
- 如果没有,就处理 tool calls
如果模型已经给出最终文本,流程结束。
如果模型请求工具,就把每个工具调用交给安全策略判断,再决定是允许、确认还是阻断。
3.3 预算控制:不是无限跑
这段实现很实用:
max_steps:最多能跑多少步token_budget:总 token 上限cost_budget_usd:成本上限
这三个限制让系统不会在异常任务里失控。很多 demo 系统的问题不是“不工作”,而是“工作得太久还停不下来”。这里至少把刹车装上了。
3.4 截图去重:减少重复上下文
我觉得这是个很工程化的小细节。
AgentCore 会记录已经见过的 image_hash,如果下一张截图没变化,就把 base64 图像省掉,只保留“未变化”的系统提示。
这类优化看起来不起眼,但对长任务很关键:
- 少传重复图像
- 少烧 token
- 少让模型在无变化画面上浪费注意力
computer use 里,截图是最贵的上下文之一,这种去重值得保留。
四、安全层:允许、确认、阻断是怎么分的
这仓库里最值得夸的一点,是它没有把“安全”当成一句空话,而是做成了明确的策略对象。
SafetyPolicy.evaluate() 会对不同工具调用给出三种结果:
ALLOWCONFIRMBLOCK
4.1 bash:默认先确认
对于 bash 命令,策略不会一刀切放行。
它会先识别一些低风险命令,比如浏览器探测、工作区只读读取之类的操作;其他命令默认要求确认。
这很重要,因为 computer use 里真正危险的往往不是模型“说错话”,而是它在 shell 里顺手把环境改了。
4.2 text_editor:读可以放行,改通常要确认
对文本编辑器工具,低风险查看行为可以允许,其他修改行为走确认。
这比“所有编辑都放行”靠谱得多。原因很简单:computer use 的价值是自动化,不是让模型在没有边界的情况下乱改文件。
4.3 computer typing:敏感内容会触发确认
对于 type 这类动作,如果文本里出现 password、credit card 这类敏感词,会转成确认。
这是个很实用的最后防线。因为很多风险不是“鼠标点错了”,而是模型开始往敏感输入框里写东西。
4.4 硬性阻断:越界动作直接拦下
如果 tool call 本身不合法,比如显示尺寸不匹配,策略会直接 BLOCK。
这说明它不是只做“软提醒”,而是会真的拒绝危险输入。
4.5 人工确认的闭环
当策略返回 CONFIRM 时,AgentCore 不会继续执行,而是把流程停在 waiting_for_confirmation。
用户批准后,系统再调用 continue_after_confirmation 把 pending tool call 执行掉,然后继续后续循环。
这就是这套系统最关键的控制点:
- 让模型继续自主跑
- 但把高风险动作拉回人类审查
computer use 真正可落地,不靠“模型更聪明”,而靠“边界更清楚”。
五、工作区隔离:文件为什么不会乱飞
文件隔离是这个仓库另外一个值得说清楚的点。
5.1 每个 run 一个 workspace
WorkspaceManager.create_run_workspace(run_id) 会为每个 run 创建独立目录:
- uploads
- outputs
这意味着任务级别的数据是分开的,不会互相串。
5.2 路径逃逸被拦住
resolve_user_path() 会先把用户路径 resolve,再检查它是否仍然位于当前 workspace 内。
如果不是,就直接报错。
这一步很小,但非常关键。因为一旦允许路径逃逸,沙箱隔离就只是纸面上的。
5.3 上传和下载都走工作区
API 层提供了:
- 文件上传
- 文件列表
- 文件下载
AI 能处理的是这个 run 的 workspace,而不是你整台机器。
这也是我愿意把这个仓库称为“工程上靠谱”的原因之一:它知道什么该开放,什么必须关起来。
六、这套实现的取舍
我觉得这个仓库有几个很明确的取舍,值得记录下来。
7.1 它优先做“本地可用”,不是“无限抽象”
很多 Agent 项目一上来就想做成平台化框架,最后每一层都很虚。
这个仓库反过来,先把一个本地可用的 computer use 产品跑通,再谈扩展。
这种顺序是对的。
7.2 run 状态目前是内存态
从 routes.py 能看出来,runs 目前是一个进程内字典。
这对本地 demo 很方便,但也意味着:
- 服务重启后状态会丢
- 不能天然多实例共享
如果后面要做生产化,持久化层肯定要补上。
7.3 安全策略是“默认保守”
这是我最认可的地方。
它没有试图证明“AI 什么都能自己做”,而是把高风险操作显式拉回确认流程。
这种设计虽然不够“爽”,但是真的能减少事故。
7.4 runtime 和主服务分离
这个决定会让系统多一点部署复杂度,但换来的是:
- 执行环境隔离
- 更清晰的故障边界
- 更容易重启 runtime
对 computer use 这种任务型系统来说,这笔账值得算。
七、总结
如果把这仓库浓缩成一句话,我会说:
它不是在“做一个会点鼠标的模型”,而是在搭一个可控的 computer use 运行时。
它最值得学习的地方,不是某个炫技 API,而是整个工程边界的划分:
- UI 只负责展示和交互
- API 负责状态和入口
- AgentCore 负责决策循环
- SafetyPolicy 负责风险边界
- Runtime 负责实际执行
- WorkspaceManager 负责文件隔离
这套思路放到任何 agent 类项目里都成立。
如果你也在做 computer use、浏览器自动化、桌面自动化,或者想把 LLM 从“问答”推进到“执行”,这个仓库很值得读一遍。
参考资料: